VMware NSX and 3rd Party Integration SVM Failure Scenarios
Today one of my peers asked this question and I found out that I was a bit lacking on that area, so I decided to do some due diligence and learn about the subject which lead to writing this post as I couldn’t find a definitive KB or article that reflects on these failure scenarios, the blog covers network introspection at this point in time and once I do further tests with guest introspection I will update this blog post.
As we all know 3rd party integration with VMware NSX is pretty much one of NSX’s strongest pillars within the ecosystem as this leverages the customer to get the benefit of both worlds without compromising on losing any feature that has not been built-into NSX in an out-of-the-box fashion.
One of the solid questions that are asked is about failure scenarios when having an integration with 3rd party vendors, what happens if an SVM fails? What is the expected behavior? How to mitigate against that behavior?
First lets specify the failure scenarios:
- ESXi host failure.
- SVM appliance failure.
These are the main scenarios that one would look at when approaching such a discussion, so lets go through the process of each:
- ESXi host failure:
- HA kicks in.
- All the virtual machines are restarted on some other nodes in the cluster.
- The virtual machines will now be handled by the other SVMs on the other hosts.
- SVM failure (an SVM is coupled per host host upon deployment and it cannot be moved or be part of HA):
- Restart the SVM.
- Spin up a new SVM by deleting the failing one and repairing the service integration via NSX Networking and Security plugin in the installation menu at the Service Deployment tab.
The first scenario is normal and is pretty much expected and the result could be foreseen, on the other hand with the second scenario and because this is a third party integration we need to keep a keen eye on the behavior.
So the big question! What happens if an SVM fails to the VMs in terms of applied policies? Lets take a step back and look at the bigger picture, since this is an integration then this is allotted a slot in the VM’s I/O Chain (read this if you do not know what is an I/O chain) and slot-4 is where the integration stuff goes and where the policies get attached.
To check the state of the I/O chain we need to do it from the CLI via the NSX Manager, I will show you two examples:
- A virtual machine in an NSX setup with no integration services:
- Connect to the NSX manager via SSH: show dfw host host-10 summarize-dvfilter (the IDs are values are based on my homelab, please make sure to change these to match your setup).
- I have only selected the output related to the VM (VM1S2):
- world 244363 vmm0:VM1S2 vcUuid:’50 2d b6 09 f2 a5 f8 05-85 05 1b 3b 8a 7e a3 33′
port 33554454 VM1S2.eth0
vNic slot 2
name: nic-244363-eth0-vmware-sfw.2
agentName: vmware-sfw
state: IOChain Attached
vmState: Detached
failurePolicy: failClosed
slowPathID: none
filter source: Dynamic Filter Creation
vNic slot 1
name: nic-244363-eth0-dvfilter-generic-vmware-swsec.1
agentName: dvfilter-generic-vmware-swsec
state: IOChain Attached
vmState: Detached
failurePolicy: failClosed
slowPathID: none
filter source: Alternate Opaque Channel
- world 244363 vmm0:VM1S2 vcUuid:’50 2d b6 09 f2 a5 f8 05-85 05 1b 3b 8a 7e a3 33′
- A virtual machine in an NSX setup with integration services:
- Connect to the NSX manager via SSH: show dfw host host-10 summarize-dvfilter (the IDs are values are based on my homelab, please make sure to change these to match your setup).
- I have only selected the output related to the VM (VM1S1):
- world 168252 vmm0:VM1S1 vcUuid:’50 2d ab 38 d6 2e 97 47-70 5b 29 23 9b 01 ec cb’
port 33554461 VM1S1.eth0
vNic slot 2
name: nic-168252-eth0-vmware-sfw.2
agentName: vmware-sfw
state: IOChain Attached
vmState: Detached
failurePolicy: failClosed
slowPathID: none
filter source: Dynamic Filter Creation
vNic slot 1
name: nic-168252-eth0-dvfilter-generic-vmware-swsec.1
agentName: dvfilter-generic-vmware-swsec
state: IOChain Attached
vmState: Detached
failurePolicy: failClosed
slowPathID: none
filter source: Alternate Opaque Channel
vNic slot 4
name: nic-168252-eth0-serviceinstance-4.4
agentName: serviceinstance-4
state: IOChain Attached
vmState: Attached
failurePolicy: failClosed
slowPathID: 18020
filter source: Dynamic Filter Creation
- world 168252 vmm0:VM1S1 vcUuid:’50 2d ab 38 d6 2e 97 47-70 5b 29 23 9b 01 ec cb’
Notice that in the second examlpe (VM1S1) we have an additional slot which is vNic slot 4 and this is where the integration happens, but this is not what we’re keen on. What you should really notice is that there is an attributed called failurePolicy and this the magic attribute which handles the behavior of a VM in case the service integration fails (namely the virtual appliance failure).
There are two modes for this policy:
- failOpen:
- When this is shown then when a failure takes place the virtual machine should be allowed to bypass all rules (equals to no security policies applied).
- failClosed:
- When this is shown then when a failure takes place the virtual machine should NOT be allowed to send out any traffic and all is blocked.
The default policy imposed by NSX is failClosed to the I/O chain slots, but after delving into the configuration (which I will show you in later on) I found that there is not an actual attributed called failClosed and failClosed is just a term that is displayed in the slot to reflect the state.
The attributed which could be modified is failOpen and it takes a boolean for its value (either true of false) and when you set this value to true then you would have a failOpen state and when you set the value to false you will have a failClosed state.
My tests were based on Frotigate’s integration with NSX but after researching most of the vendors do utilize this mechanism to handle SVM failure, within each service definition exists an instance and each instance has something called service profiles (this is what you see when you enable rules redirection policy in the service composer), and you can create multiple service profiles and use these profiles when doing the redirection; for example you have some virtual machines that in case an SVM fails you always want them to be reachable and you have another set that you do not want to compromise security for them at all so one profile would have the failOpen set as true whereas the other would have it set as false.
How to:
- Networking and Security Plug-in -> Service Definition ->[Select/double click on the 3rd Party Vendor Service to edit it]
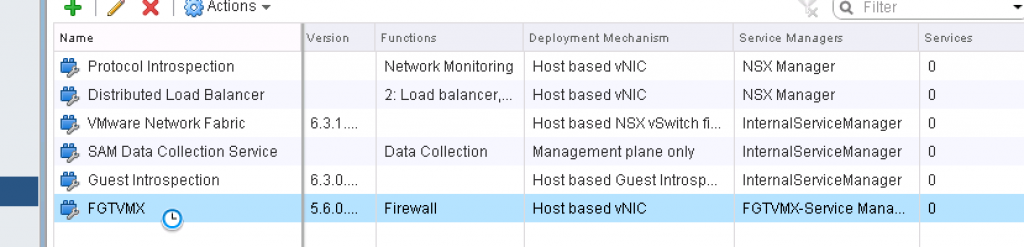
- Services Instances -> Select the instance -> Service Profiles -> Select the service profiles -> Select the profile
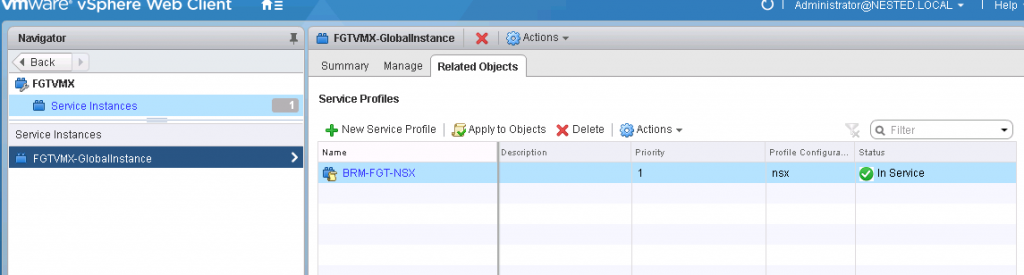
- In the Manage tab there are two sections.
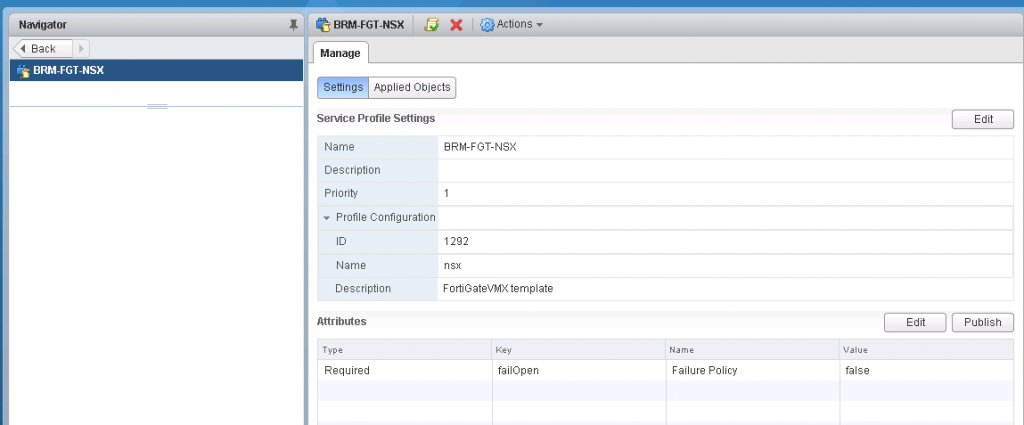
- Go to the attributes section -> Edit -> Change the failOpen to either true or false as needed
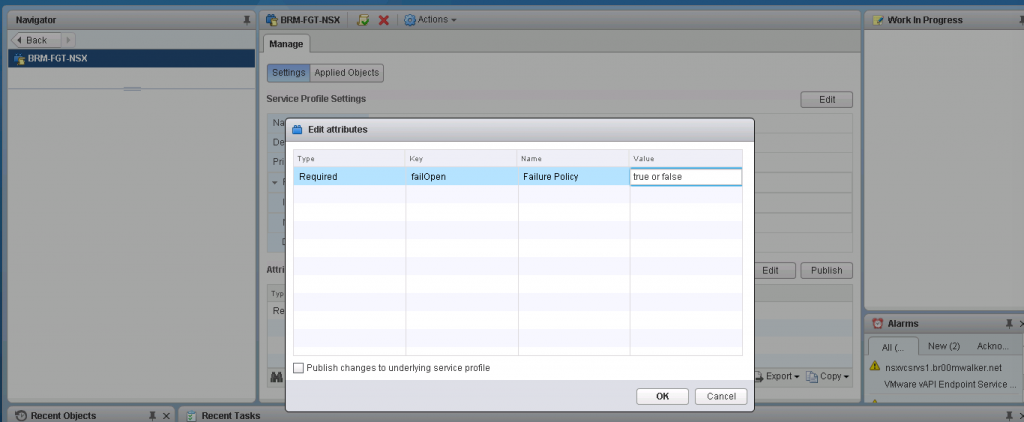
My validation:
- I created an IP set for the VM1S1 virtual machine.
- Create a security group and added the VM1S1 to it.
- Created an inbound and outbound redirection policy.
- Applied the policy to the VM1S1 security group.
- I created a policy on Fortigate to allow traffic to and from VM1S1.
- I launched a ping from within the VM and from and my laptop.
- failOpen true:
- Shutdown the SVM and traffic was still flowing without any issues.
- failOpen false: (you need to give this sometime when publishing the new value, and make sure that it has been applied (via show dfw CLI)
- Shutdown the SVM and the traffic immediately stops both sides.
I haven’t found anything which automates an SVM failure, in such a way that if an appliance fails a new appliance gets deployed in its stead or if the appliance hangs for some reason something would detect this failure and restarts it in an attempt to recover its health status. So if you (my precious reader) know about such a thing please comment on the this blog post and I will make sure to update it as well.
I hope this clears the fog around this topic and thank you for taking the time to read it.
(Abdullah)^2
Hi Abdullah, very nice and detailed article. I’m also looking for a mechanism that can automate SVM failover. We have deployed Palo Alto NGFW in NSX for customer, we are looking for a way to automate the NGFW failover but so far no luck. Do share if you have found a workaround. Thanks